Discovering State-of-the-Art Reinforcement Learning Algorithms
Every RL algorithm you've ever heard of was created by a human. This DeepMind Nature paper asks whether a machine can also do it. The answer is yes: DiscoRL beats every manually designed RL algorithm on Atari and generalizes to benchmarks it was never trained on.
How it works
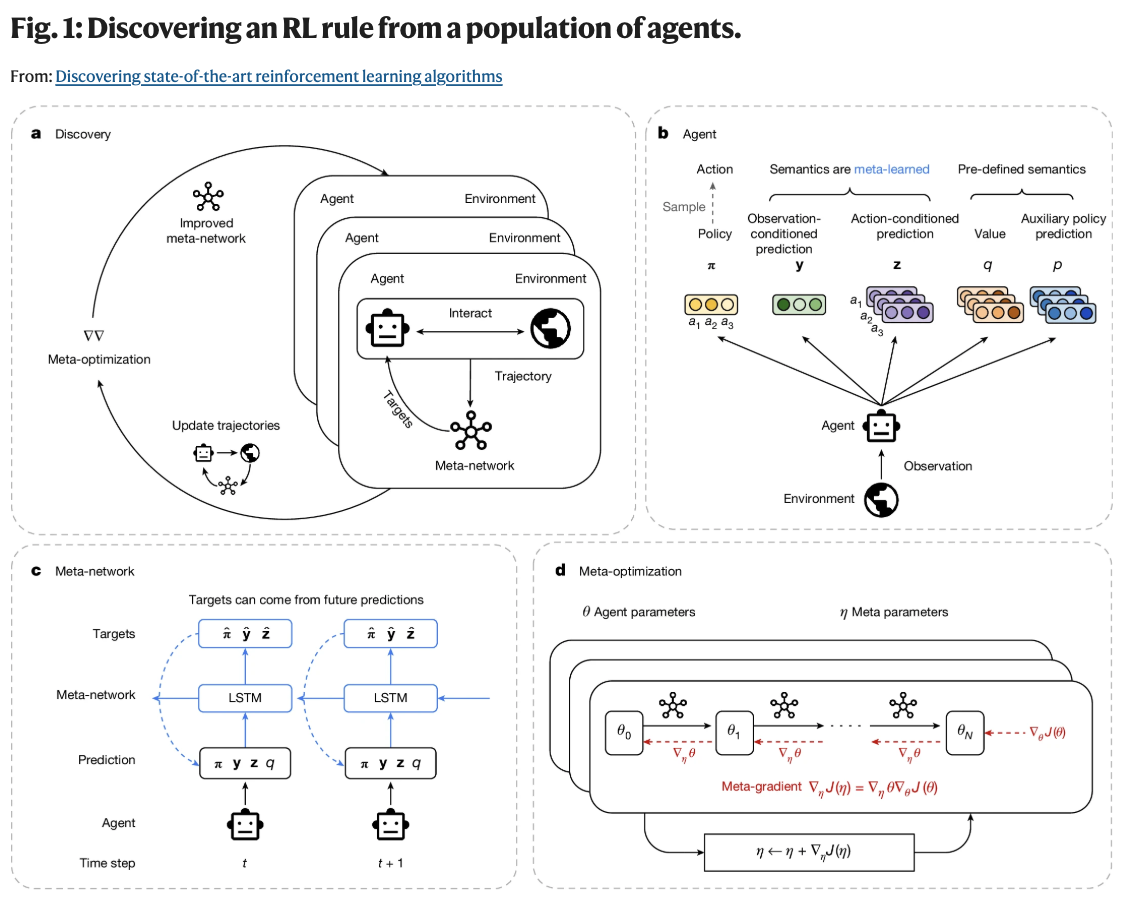 Fig. 1: The full discovery loop, from agent architecture to meta-optimization.
Fig. 1: The full discovery loop, from agent architecture to meta-optimization.
The setup involves two nested loops (Fig. 1). A population of agents interact with environments and update their parameters using the current learning rule. That rule is represented by a meta-network, which gets updated to make the agents learn better. The agent minimizes:
where is KL divergence. The targets come from the meta-network, not the researcher. The prediction types mirror RL's classic prediction/control split: is observation-conditioned (like a state-value function), is action-conditioned (like a Q-function). This makes the search space expressive enough to rediscover existing RL concepts while remaining open to new ones.
The meta-objective maximizes cumulative agent returns across environments:
This meta-gradient backpropagates through 20 unrolled agent update steps. A second "meta-RNN" unrolls forward across parameter updates , giving the rule access to the agent's learning dynamics over its lifetime.
Results
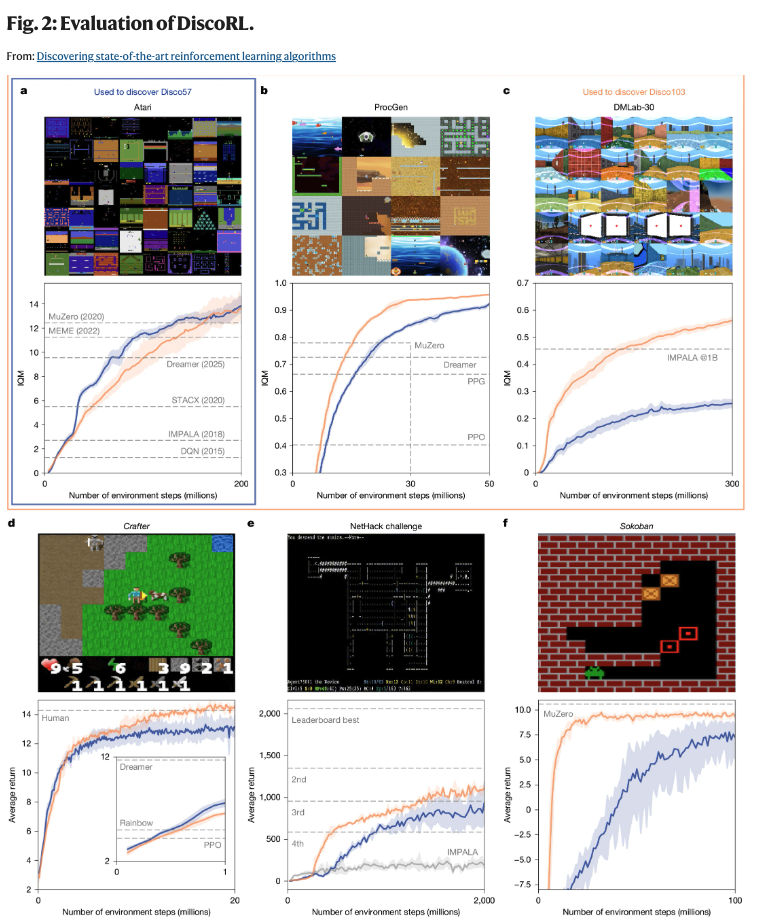 Disco57 (blue) from Atari; Disco103 (orange) from Atari + ProcGen + DMLab-30. Dashed lines: MuZero, MEME, Dreamer, STACX, IMPALA, DQN, PPG, PPO, Rainbow.
Disco57 (blue) from Atari; Disco103 (orange) from Atari + ProcGen + DMLab-30. Dashed lines: MuZero, MEME, Dreamer, STACX, IMPALA, DQN, PPG, PPO, Rainbow.
| Benchmark | Result |
|---|---|
| Atari 57 | IQM 13.86, best ever reported |
| ProcGen (zero-shot) | Beats all published methods including MuZero |
| NetHack NeurIPS 2021 | 3rd of 40+ teams, no domain knowledge |
| Crafter | Near human-level (Disco103) |
| Sokoban | Approaches MuZero (Disco103) |
ProcGen is the most striking result: DiscoRL never saw those environments during training and still beat MuZero. Scaling from 57 to 103 training environments improved performance on every benchmark, including held-out ones.
What did it discover?
The and predictions carry more information about upcoming rewards and future policy entropy than the policy or value function. Gradient analysis in Beam Rider shows them attending to distant enemies, while the policy watches nearby threats and the value function tracks the scoreboard.
Most interestingly, perturbing strongly shifts the current target , meaning the meta-network uses future predictions to construct current targets. It rediscovered bootstrapping on its own!
The rule quality scales with environment diversity and shows no sign of saturation. Same story as language models, now applied to algorithm discovery.
Big Picture
If AI can infer RL rules from a population of agents interacting with an environment, can the same be done for general AI systems?
Oh et al., Discovering state-of-the-art reinforcement learning algorithms, Nature 648, 312–319 (2025). https://www.nature.com/articles/s41586-025-09761-x