Mining Better Activation Functions with LLMs
Google DeepMind researchers recently explored whether large language models could help discover better activation functions for neural networks. Their approach uses evolutionary search where an LLM proposes variations of activation functions, which are then tested on carefully designed synthetic problems. The surprising result: functions discovered this way actually transfer to real-world benchmarks and improve out-of-distribution generalization.
The Setup
Choosing the right activation function has long been a design decision in deep learning. ReLU became popular for training stability, GELU for slightly better performance. But these choices were motivated primarily by in-distribution metrics. What if we optimized specifically for generalization instead?
The challenge is that directly searching for activation functions on large benchmarks is prohibitively expensive. Train a model, evaluate it, repeat thousands of times? That's the neural architecture search (NAS) problem all over again.
The key insight here is to use synthetic proxy tasks. Train tiny models on simple functions (polynomials, harmonic waves, physics equations) where you can deliberately create an out-of-distribution split. If an activation function helps a network extrapolate on these toy problems, maybe that property transfers to real tasks.
How AlphaEvolve Works
Previous work on discovering activation functions (see Ramachandran et al. 2018) searched by combining a small number of predefined primitive operators. This paper takes a different approach. Using the AlphaEvolve framework, they search over arbitrary Python functions, limited only by a compute budget.
AlphaEvolve maintains a database of the best activation functions discovered so far. An ensemble of LLMs samples from this database and proposes new candidate functions. These candidates get plugged into small MLPs and trained on synthetic datasets (takes seconds per evaluation). Evaluators then score each function based on its OOD test performance. High-scoring functions get added back to the database, creating a continuous evolutionary cycle.
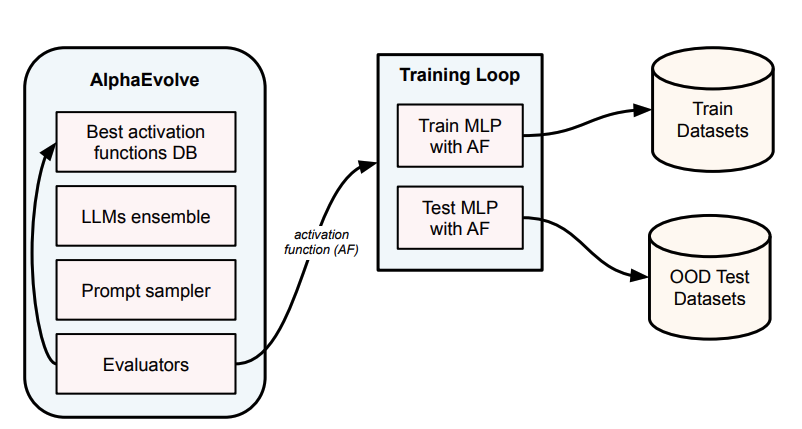 Figure 1: AlphaEvolve maintains a database of top-performing activation functions. LLMs propose new candidates by sampling from this database, which are then evaluated via a training loop on synthetic data. The evaluators score performance on OOD test sets, and successful functions are added back to the database.
Figure 1: AlphaEvolve maintains a database of top-performing activation functions. LLMs propose new candidates by sampling from this database, which are then evaluated via a training loop on synthetic data. The evaluators score performance on OOD test sets, and successful functions are added back to the database.
The key insight: by maintaining a database of diverse, high-performing programs rather than converging to a single optimum, the system can explore different solutions and let the LLM learn from what's worked before.
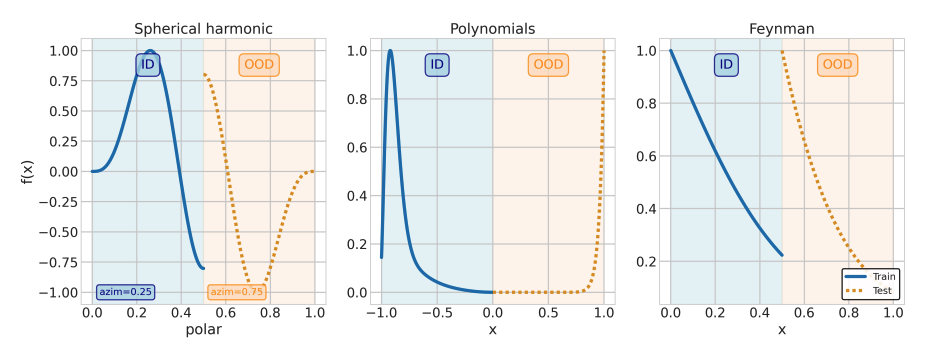 Figure 2: The synthetic datasets use disjoint input ranges for training (ID, blue) and testing (OOD, orange). Each function type tests different aspects of generalization: harmonic functions test periodicity, polynomials test extrapolation, and Feynman equations test physics-inspired complexity.
Figure 2: The synthetic datasets use disjoint input ranges for training (ID, blue) and testing (OOD, orange). Each function type tests different aspects of generalization: harmonic functions test periodicity, polynomials test extrapolation, and Feynman equations test physics-inspired complexity.
The fitness function is crucial here. They optimize for OOD test loss, not training loss. This biases the search toward functions that genuinely help networks generalize rather than just memorize.
What Got Discovered
After running this evolutionary process, a pattern emerged. The best functions weren't exotic or complicated. They were variations on GELU with an added periodic component:
GELU-Sine:
GELUSine(x) = GELU(x) + 0.1 × sin(x)
GELU-Sinc-Perturbation:
GELUSinc(x) = GELU(x) × (1 + 0.5 × sinc(x))
= GELU(x) × (1 + sin(πx)/(2πx))
Why periodic functions? The authors speculate that periodicity creates a form of memory. Patterns seen during training recur naturally in the activation landscape, making it easier for the network to retrieve and apply them when extrapolating.
On the synthetic benchmarks, the improvement was substantial:
| Activation | OOD Test Loss | Training Loss |
|---|---|---|
| GELU-Sinc | 68.7 | 2.2 |
| GELU-Sine | 54.7 | 1.4 |
| GELU | 78.8 | 2.0 |
| ReLU | 93.1 | 3.5 |
GELU-Sinc cut the OOD test loss by 26% compared to standard GELU, and by 41% compared to ReLU.
The Real Test: Does It Transfer?
Synthetic benchmarks are one thing. Real-world performance is another. They evaluated the discovered functions on:
- CIFAR-10 and ImageNet (standard image classification)
- CLRS-30 (algorithmic reasoning with explicit size generalization tests)
- ogbg-molhiv (molecular property prediction with scaffold splits)
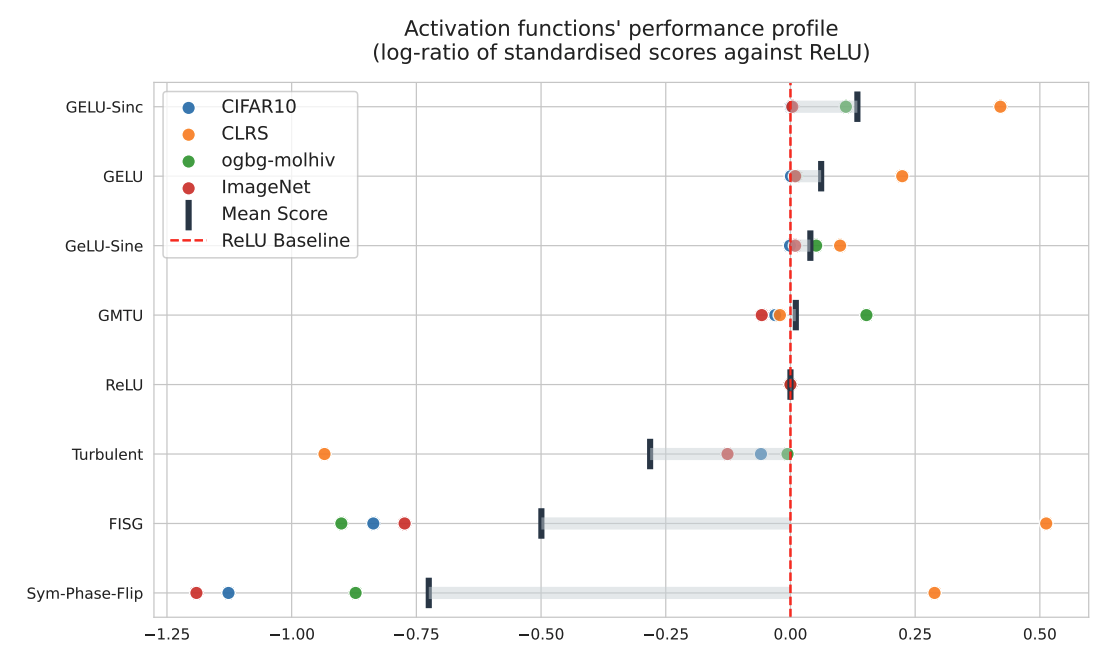 Figure 6: Performance of discovered activation functions relative to ReLU baseline (log-ratio of standardized scores). GELU-Sinc performs best overall, with strong improvements on CLRS-30 (orange dots) without sacrificing performance on other tasks. Batch-aware functions like Turbulent and FISG fail catastrophically on some benchmarks.
Figure 6: Performance of discovered activation functions relative to ReLU baseline (log-ratio of standardized scores). GELU-Sinc performs best overall, with strong improvements on CLRS-30 (orange dots) without sacrificing performance on other tasks. Batch-aware functions like Turbulent and FISG fail catastrophically on some benchmarks.
The results are encouraging. GELU-Sinc-Perturbation shows the strongest overall performance, particularly on CLRS-30 where generalization matters most. Critically, it doesn't hurt performance on standard image benchmarks either.
An interesting failure mode also emerged. Some discovered functions computed statistics across the batch dimension. These performed well in the controlled synthetic environment but crashed spectacularly on real datasets (sometimes literally, with out-of-memory errors). The lesson: functions that rely on batch statistics can overfit to distributional quirks of the training setup. Pointwise functions proved more robust.
What This Means
Three takeaways stand out:
-
Synthetic proxies work. You don't need ImageNet-scale experiments to discover useful architectural components. Carefully designed toy problems can surface properties that matter at scale.
-
Optimizing for the right thing matters. Explicitly targeting OOD performance during search led to functions that actually generalize better. Most prior work optimized for training speed or in-distribution accuracy.
-
Simplicity wins. The best functions weren't elaborate constructions. They were GELU plus a small periodic perturbation. Sometimes the search space of useful modifications is surprisingly constrained.
Implementation
If you want to try GELU-Sinc-Perturbation in your own models:
import torch
import torch.nn.functional as F
def gelu_sinc(x):
"""GELU-Sinc-Perturbation activation function"""
gelu_term = F.gelu(x)
pi_x = torch.pi * x
sinc_term = torch.where(
torch.abs(x) < 1e-7,
torch.ones_like(x),
torch.sin(pi_x) / pi_x
)
return gelu_term * (1 + 0.5 * sinc_term)
Drop it in wherever you'd use ReLU or GELU. Whether it helps will depend on whether your task involves the kind of generalization these functions were selected for.
Open Questions
-
Why do periodic functions help? The empirical results are clear, but the mechanism isn't. Does periodicity affect the loss landscape? The gradient flow? The internal representations? This deserves theoretical analysis.
-
How far can this transfer? The current work tests on relatively standard benchmarks. Would these functions help with very different domains like reinforcement learning or language modeling?
-
Can we do better with learned parameters? These functions have fixed coefficients (the 0.1 in GELU-Sine, the 0.5 in GELU-Sinc). What if those were learnable parameters that adapted during training?
Closing Thoughts
This paper demonstrates that cheap synthetic experiments can guide the discovery of architectural components that transfer to real benchmarks. For activation functions specifically, it identified modifications that improve OOD generalization without sacrificing standard performance.
The broader context matters more than the specific functions discovered. As the authors note, this work fits within efforts to improve the rate of novel architecture discovery. Any significant improvements in automated architecture search could eventually transfer to more potent self-improving AI systems.
Paper Reference: Mining Generalizable Activation Functions arXiv:2602.05688v1 [cs.LG] 5 Feb 2026